Die zunehmende Digitalisierung in vielen Anwendungsbereichen der Wirtschaft, Verwaltung und Wissenschaft führt zu ständig wachsenden Datenmengen und damit immer häufiger zur Notwendigkeit, datenbasierte Prognosen zu erstellen und Zusammenhänge in großen heterogenen Datenmengen zu erkennen. Machine Learning (ML) ist ein Kernthema in diesem Bereich, mit dem sich 64% aller deutschen Unternehmen aktiv beschäftigen. Die effiziente Anwendung aktueller ML-Verfahren erfordert jedoch ein sehr hohes Maß an Expertenwissen, was einer verbreiteten Nutzung von Machine Learning-Ansätzen, insbesondere durch kleine und mittlere Unternehmen (KMU), im Wege steht. Die zentrale Forschungsfrage des Simple-ML Projekts lautet daher:
Zielgruppe: Unternehmen, Behörden und Wissenschaft können gleichermaßen von einem effizienten Einsatz von ML-Verfahren profitieren. Das Simple-ML Konsortium adressiert insbesondere den Bedarf von IT-DienstleisterInnen im Bereich Datenanalyse und Softwareentwicklung. Diese sind oft KMUs, die sich auf die Entwicklung domänenspezifischer Lösungen spezialisiert haben. Bei diesen Unternehmen ist Expertise im ML-Bereich oft nur begrenzt vorhanden, so dass ML-Lösungen nur mit einem hohen Aufwand und hohen Kosten realisierbar sind. Die Ergebnisse des Simple-ML Projekts sollen IT-Fachleute ohne signifikante ML-Expertise in die Lage versetzen Anwendungen auf Basis von ML-Verfahren effizient zu erstellen. Erfahrene AnwenderInnen sollen insbesondere von der effizienten Erstellung und Wiederverwendbarkeit der ML-Lösungen für komplexe Fragestellungen profitieren.
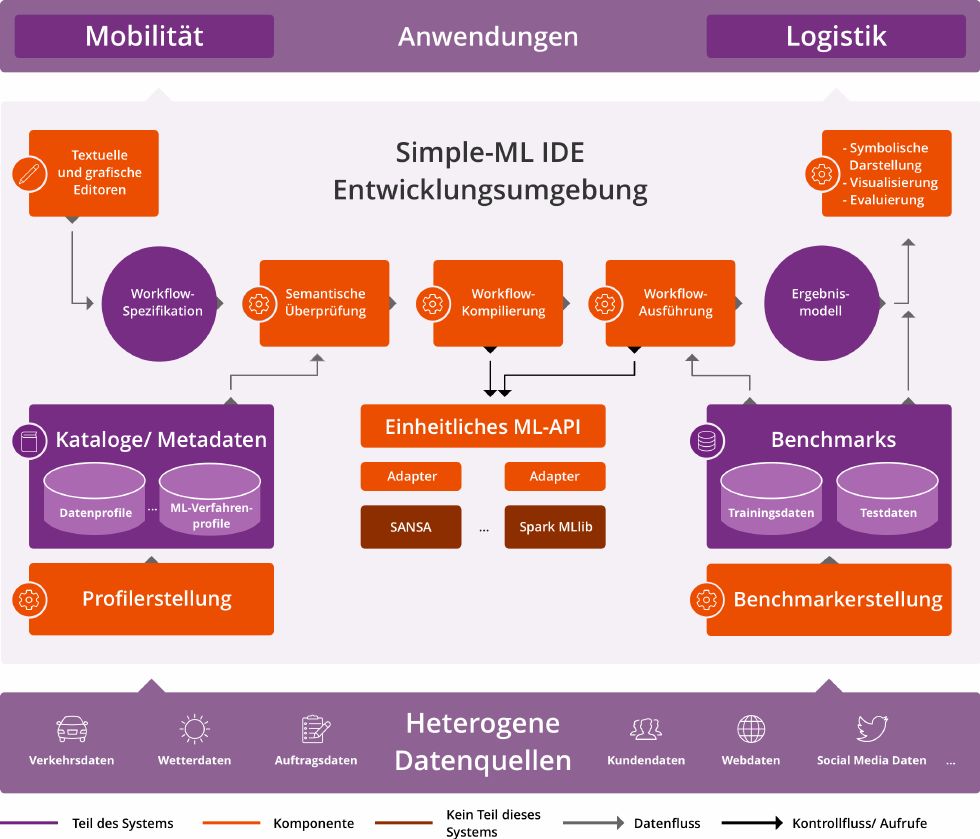
Ziele: Das Hauptziel des Simple-ML Projekts ist es, die
- (Z1) Benutzbarkeit aktueller ML-Verfahren signifikant zu erhöhen, so dass diese von einem breiteren Anwenderkreis für komplexe Fragestellungen effizient eingesetzt werden können, insbesondere durch Entwicklung von Formalismen die eine Modellierung der ML-Lösungen auf einem hohen Abstraktionsniveau ermöglichen.
Dabei werden folgende kritische Aspekte mit berücksichtigt:
- (Z2) Robustheit von ML-Workflows (Arbeitsabläufe) durch: 1.) bessere Unterstützung heterogener Datenquellen durch Anwendung von semantischen Technologien, und 2.) Entwicklung von Methoden zur automatischen Überprüfung der korrekten Komposition der ML-Workflows basierend auf semantischen Beschreibungen,
- (Z3) Erklärbarkeit und Transparenz der erlernten Modelle und Analyseergebnisse durch Weiterentwicklung der symbolischen ML-Methoden, interaktiven Visualisierungen und Benchmarks,
- (Z4) Effizienz und Skalierbarkeit der erstellten Anwendungen durch den Aufbau auf skalierbare ML-Frameworks und Entwicklung der ebenfalls hoch skalierbaren ML-Algorithmen, sowie
- (Z5) Wiederverwendbarkeit der ML-Workflows und deren Komponenten durch semantische Beschreibungen und Open Source Lösungen.